
Each year, the chair of computer architecture offers the “supercomputing” lab lecture, which serves the purpose of preparing a team of six students to participate in the student cluster competition at ISC. In the competition at ISC18, twelve teams from all over the world competed to get the highest performance out of their self-assembled mini-clusters for a set of applications under a 3000 W power constraint. Once more, the team from Friedrich-Alexander-University Erlangen-Nuremberg, advised by Johannes Hofmann and Alexander Ditter from the chair of computer architecture, managed to bring the prestigious LINPACK award home to Erlangen!

The following provides an account how some of the competition’s challenges were addressed, so feel free to continue reading if you’re interested in the technical details. However, before going into these details, we’d like to extend our gratitude to our sponsors, without whom this whole affair would not have been possible: We’d like to thank HPE in general and Patrick Martin, our contact at HPE, in particular for providing us with a system according to our specifications and loaning it to us for free! We’d also like to thank GCS in general and Regina Weigand, our contact at GCS, in particular, as well as SPPEXA, for providing us with financial support to help with competition-related expenses. Now, with pleasantries out of the way, let’s get down to business…
The 3000 W power limit enforced during the competition serves as equalizing factor and makes it necessary to work smart, not hard. You cannot simply ask your sponsor for a crazy amount of hardware and win the battle for performance by superior numbers. Instead, you have to optimize your system for energy efficiency, which in the case of LINPACK means floating-point operations per second per Watt (Flop/s/W), for the overall performance (Flop/s) is given by multiplying the system’s energy efficiency (Flop/s/W) with the available power budget of 3000 W.
With energy efficiency the optimization target, CPUs were off the table: Although we had observed significant energy-efficiency improvements in recent CPUs (e.g., for LINPACK we got up to 8.1 GFlop/s/W on a 28-core Intel Skylake-SP Xeon Platinum 8170 processor compared to 4.6 GFlop/s/W on a 18-core Broadwell-EP Xeon E5-2697 v4 one), they were at least a factor of three behind contemporary GPUs in terms of GFlop/s/W. The obvious strategy thus consisted of packing as many GPUs as made sense into our nodes and use the CPUs merely to drive the host systems.
For the competition, we went with an HPE Apollo 6500 Gen9 system, comprising two HPE XL270d compute nodes connected directly via InfiniBand EDR. Each of the nodes was equipped with two 14-core Intel Xeon E5-2690 v4 processors, 256 GB of RAM, and Nvidia GPUs. In the previous competition, which took place in June 2017, we used (then state-of-the-art) Nvidia Tesla P100 GPUs. For the 2018 competition, we could get our hands on V100 GPUs, which were released in December 2017. Now the crux of the matter was determining how many GPUs to put into each of the host systems. Without GPUs, the base power of each node (i.e., the power used for CPUs, RAM, blowers, and so on) was around 250 W. The naive strategy would have been to divide the remaining power budget of 2500 W by the 250-Watt TDP of a V100 GPU. This strategy would have told us to use ten GPUs in total, corresponding to five per node. The LINPACK performance of a single V100 GPU (16 GB, PCIe version) running in Turbo mode—and therefore fully exhausting the 250 W TDP—is around 4.5 TFlop/s. So, for the ten-GPU setup we could have expected a performance of around 45 TFlop/s—not bad, considering this would have been a 42% improvement to our previous P100-based record of 31.7 TFlop/s.
However, there is room for improvement. During investigations carried out for last year’s competition, the GPU core frequency was identified as variable with significant impact on energy efficiency. This relationship between frequency and energy efficiency is demonstrated in Figure 1. For one thing, the figure quantifies the energy-efficiency improvement of the V100 compared to its predecessor. For another, the data indicates that Turbo mode, where GPU cores are clocked at around 1380 MHz, is not a good choice when optimizing for energy efficiency. Instead, the GPU should be clocked at 720 MHz, for at this frequency the energy-efficiency optimum of 28.1 GFlop/s/W is attained. In theory, this strategy allows for a performance of 2500 W · 28.1 GFlop/s/W = 70.2 TFlop/s—a value that is 56% higher than what can be achieved by the naive approach of running the GPUs in Turbo mode.
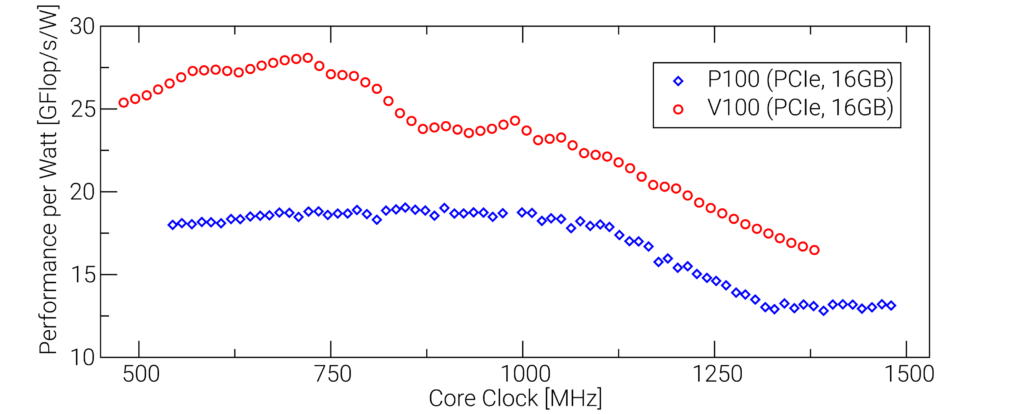
Note, however, that in practice this value was not attainable using a two-node setup, which provided room for at most sixteen GPUs: A single V100 GPU consumes 118 W when running at the most energy-efficient frequency of 720 MHz, which means a total of 21 GPUs would be required to exhaust the remaining power budget of 2500 W to achieve an energy efficiency of 28.1 GFlop/s/W. Moreover, we could get our hands on only twelve V100 GPUs (back then with a retail price tag of around $20,000 apiece, these cards were, after all, quite expensive). Nevertheless, using the approach of tuning the GPU core frequency to increase energy efficiency, we were able to get 51.7 TFlop/s out of our two-node twelve-GPU setup—exactly 20.0 TFlop/s more than our previous record of 31.7 TFlop/s set at ISC17. It goes without saying that this was enough to secure the LINPACK award in this year’s competition.